Context at inference.Not across your integration layer.
Cut token costs by up to 90%. Memory at the model layer, not across brittle connectors.














01
Struggling with token costs?
You're not alone.
Leaders are capping spend, cutting tools, and rethinking every model call.
memory decay // each session resets
02
Poor memory recall?
Every session starts cold.
Agents forget what worked, what failed, and what your team already decided.
03
Agents blackboxing you?
You see the output.
Not the retrieval, tool calls, or reasoning that produced it.
04
Institutional knowledge fragmentation?
Context lives everywhere.
Slack, CRM, tickets, docs. Nothing shares a single source of truth.
Introducing
CORTYXIA
A zero-friction intelligence layer.
One API key swap. No rebuild, no adapters, no integration project. Unified memory, lower token spend, and full observability from day one.

Stop replaying every turn.
Pay for context once.
Full-context replay sends the entire conversation on every call. Cortyxia retrieves structured memory at inference, caps the prompt, and keeps spend bounded as sessions grow. Quality never takes the hit.
80.8%
fewer prompt tokens
10.2×
by question 50
governance eval · q50
full-context replay
cortyxia · 10.2× fewer tokens
~8k token budget
01
Intercept at inference
Your app keeps the same API call pattern. Cortyxia wraps your key: one swap, no rebuild, no new adapters.
02
Remember structurally
Facts, entities, and relationships live in a persistent memory graph, not as a growing chat log you resend every turn.
03
Assemble what matters
Relevance scoring packs only what this query needs into a fixed token budget, typically 6–12K, turn 1 or turn 50.
04 · retrieval temperature
LLMs have temperature.
So should context retrieval.
Models already let you control how creative a response is. Cortyxia lets you control how much memory comes back with each call. Turn it down for a focused answer. Turn it up when the work is complex and the model needs richer context. Still bounded. Still under your control.
Lower setting
Focused answers
Less context in the prompt. Less noise. Best for policy questions, support, and everyday lookups where you want the right fact, not the full archive.
Higher setting
Deeper context
Richer memory for complex work: coding, investigations, multi-step fixes. More structure when the task needs it, without replaying the entire conversation history.
Context size over a coding session
20 turns
Prompt tokens per turn
Focused and deeper stay flat. Full history climbs through the session.
91.5%
Fewer tokens in a focused coding session versus replaying full history.
~90%
Still cut on the deeper setting, with a bit more context when the task needed it.
100%
Bug-fix success at the highest setting, versus 73% when replaying full history.
Evaluated across four domains
Enterprise governance
80.8%
50-question session · quality held
IDE coding
91.5%
20-turn session · same code quality
SWE-style fixes
70%
Cortyxia 100% vs 73.3% baseline
LoCoMo (public)
39.8%
External benchmark
Unified Memory
Your memory should not die when you switch vendors. Cortyxia keeps one shared context layer across providers and platforms, so you can move freely without rebuilding knowledge from scratch.









Cumulative Intelligence
Every resolved ticket and strategic decision enriches your shared memory layer. No need for manual integrations, just select BYOK or BYOLLM, and use Cortyixa enabled API key and auto-connect with Salesforce, HubSpot, Slack, and more. Your entire stack intergrated within minutes, ensuring expertise compounds and insights never decay.
Zero Overhead Setup
No new adapters or platform lock-in. One-click API key swap wraps around your existing infrastructure, adding model-agnostic memory and real-time context improvement without rebuilding your agents.
Bidirectional Synchronization
Real-time bidirectional synchronization keeps every connected enterprise app in lockstep. Update once, reflect everywhere instantly. Your data flows seamlessly across your ecosystem.
OSuite Observability
Every inference, fully visible. Pick the right model, tighten prompts, catch guardrail breaks, and trace failures in one pane, without stitching tools together.
Model Comparison
Different tasks need different models. Compare cost, latency, and six quality scores side by side so you route each workload to the provider that actually performs best.
Prompt Metrics
Track quality on what you send and what comes back. System instructions, user messages, and AI replies are scored on six metrics so weak prompts surface fast.
Tracer
See exactly what happened on every call. Tools, memory, retrieval, and agent logic traced in one view, with a clear audit trail for your team.
Guardrail Check
We auto-detect the guardrails in your prompts, from persona rules like "act as a marketing bot" to hard limits like "never mention Topic X." Get alerted the moment a response breaks them.
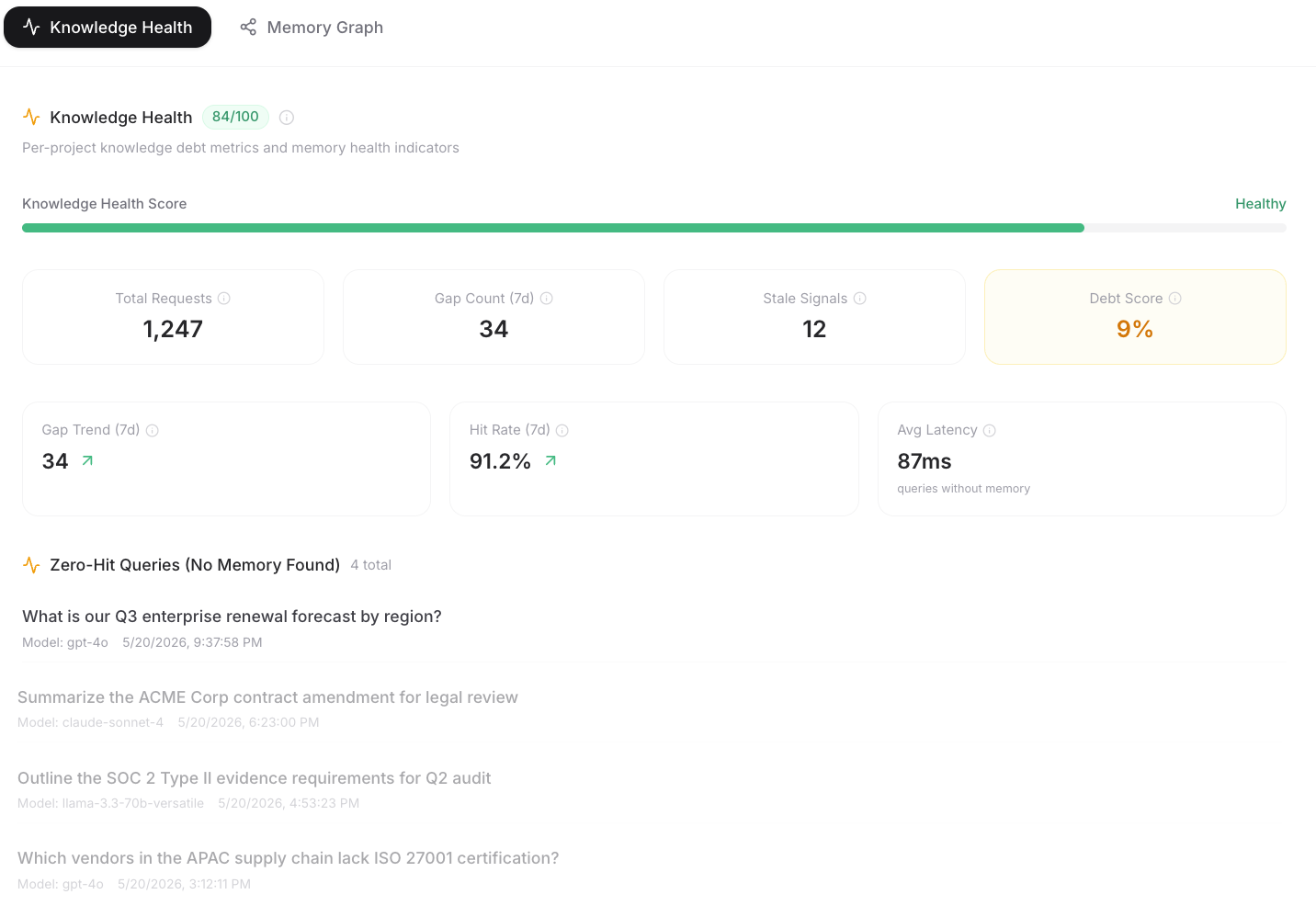
Knowledge Health
Expose what your organization knows and what your AI can use. See which business functions your AI covers with confidence, and where memory gaps leave teams without answers.
Knowledge Health & Cluster Intelligence
A command-center view of your organization's knowledge health across every business function, built for leadership visibility and the teams shipping agents in production. Track coverage gaps, stale signals, and blind spots; group queries by cluster to expose hotspots, missing caches, retrieval density, and unclustered nodes before they become silent debt. Prioritize acquisition exactly where recent queries found no relevant memory, so enterprises reduce risk and engineering teams know what to fix next.
Memory Nodes and Connections
Full visibility into how memory actually performs under load, node by node and cluster by cluster. See connection density, retrieval patterns, and how far knowledge spreads across your graph. Surface over-retrieved hotspots wasting context, under-retrieved gaps hiding institutional knowledge, and the exact nodes that need reinforcement, giving operations clear accountability and developers a precise backlog before quality drifts.

Memory Control at Scale
Control what memory is shared, who can access it, and how it stays isolated across every team and environment.
Pooled Memory
Choose what memory converges across teams and what stays locked to its own context. Share when it should, isolate when it must, with no duplication and no leakage.
Scoped Permissions
Set read, write, and admin access per namespace. Every team and agent only touches the memory it is authorized to use.
Environment Isolation
Give every project, team, and environment its own key. Production memory stays scoped and cannot cross-contaminate staging, sandboxes, or other teams.
Observability Mode
Run keys in observability-only mode. Capture telemetry and audit trails without letting monitoring traffic shape production memory.
Granular
Infrastructure
Self Host Your Data
Export Your Data for Training
Your Data, Always Yours

Weighing alternatives?
This is our view.
Cortyxia alternatives and comparisons: Mem0 alternative, Zep alternative, Graphiti alternative, Supermemory alternative, Letta alternative, MemGPT alternative, and LangMem alternative. Each card links to a full-depth Cortyxia vs guide on the blog.
Common Questions
Straight answers on how Cortyxia saves you money, keeps your data yours, and makes production AI actually work.